26.3. 日本語テキストと文字コード
日本語テキストファイルを表示してみましょう。
準備 #
例題のデータをダウンロードして,Colab で展開します.
先に Colab のノートブックを開きます HWB-iconv.ipynb

...
例題のデータをダウンロードします.
japanese-text.zip
左のサイドバーから ファイルブラウザ folder を開いて,右クリックからアップロードします
展開します.まず,画面 下端 のツールバーからターミナル terminal を起動します.

開いたターミナルで unzip コマンドを使います.
unzip j までタイプして タブキー keyboard_tab
を押すと,補完されて,ファイル名の最後まで入力されます.Archive: japanese-text.zip creating: japanese-text/ inflating: japanese-text/japanese-euc.txt inflating: japanese-text/japanese-jis.txt inflating: japanese-text/japanese-utf8.txt inflating: japanese-text/japanese-sjis.txt
tree コマンドで確認すると,
4つのファイルがあります.
今回も,tree j までタイプしたら,タブキー keyboard_tab
で補完しましょう.
japanese-text ├── japanese-euc.txt ├── japanese-jis.txt ├── japanese-sjis.txt └── japanese-utf8.txt
utf8 #
ファイルブラウザから,japanese-utf8.txt を読んで見ましょう.
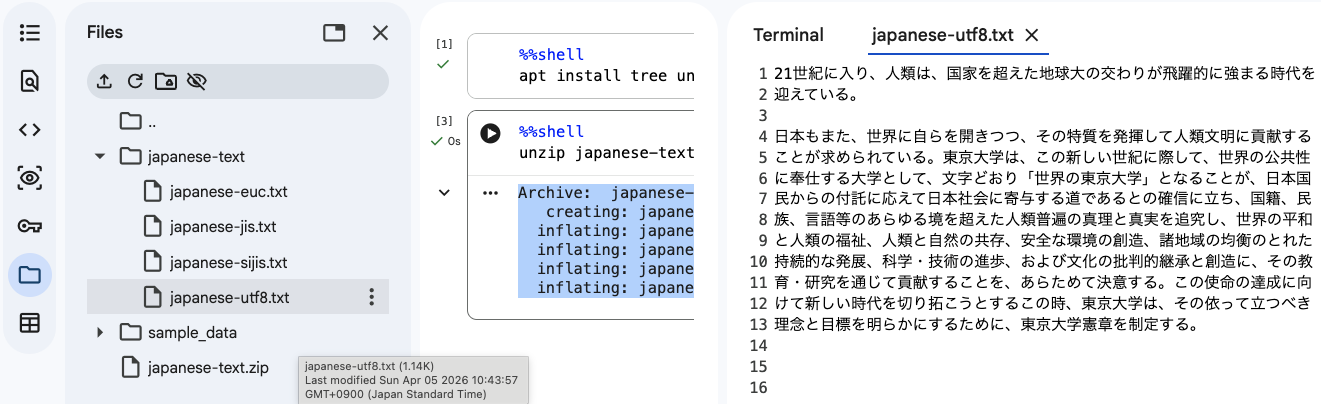
後で試しますが,他のファイルは文字化けします. utf8 を目印にファイルを正しく特定してください.ターミナルから cat コマンドでも読んで見ましょう.
cat パス は指定されたパスがテキストファイルだと信じて内容をターミナルに表示します。
補完を使って入力しましょう,cat jのあと,cat japanese-text/jのあと,cat japanese-text/japanese-uのあと,と3回使うと良いです.
21世紀に入り、人類は、国家を超えた地球大の交わりが飛躍的に強まる時代を 迎えている。 日本もまた...
ターミナルのプロンプトで cat (空白文字含む) までタイプしたあとで japanese-2 のアイコンをターミナルまでドラッグアンドドロップします。
文字コード変換 #
つづいて japanese-jis.txt を表示しましょう.ファイルブラウザで開いても,ターミナルでcat で表示しても,文字化けします。
21@$5*$KF~$j!"?MN`$O!"9q2H$rD6$($?CO5eBg$N8r$o$j$,HtLvE*$K6/$^$k;~Be$r 7^$($F$$$k!# F|K\$b$^$?!"@$3&$K<+$i$r3+$-$D$D!"$=$NFC<A$rH/4x$7$F?MN`J8L@$K9W8%$9$k ...
これはターミナルが utf-8 を期待しているのにファイルの内容が別の文字コードを使っているためです。 文字コードを変換しましょう。
nkf コマンド #
nkf は 日本語の変換で便利なコマンドです.
nkf -w filepath のように -w オプションとファイルのパスを指定すると,
utf-8 に変換して読むことができます。
21世紀に入り、人類は、...
他のファイル,japanese-euc.txt や japanese-sjis.txt も同様に読んで見ましょう.
nkf はフリーソフトウェアで homebrew などからインストールできます。iconv
iconv コマンド #
iconv コマンドは同様に変換機能を持ちますが、
より多くの言語やコードの変換ができる代わりに、ユーザが変換元のエンコーディングを指定する必要があります。
つまり文字エンコーディングが分からないファイルには使えません。
EUC-JP で書かれたファイルを UTF-8 で表示するには以下のように行います。
21世紀に入り、人類は、国家を超えた地球大の交わりが飛躍的に強まる時代を ...
コードとファイルサイズ #
4つのテキストファイルは,異なる文字コードを使っていますが,内容は同じ文章でした.
それぞれの,ファイルサイズを調べてみましょう.ls -l folder とするとフォルダ内のファイルの詳細が表示されます.
読みにくいですが,中央付近の数 (783, 855 など) がファイルサイズです.
total 16 -rw-r--r-- 1 root root 783 Apr 5 01:44 japanese-euc.txt -rw-r--r-- 1 root root 855 Apr 5 02:38 japanese-jis.txt -rw-r--r-- 1 root root 783 Apr 5 01:44 japanese-sijis.txt -rw-r--r-- 1 root root 1166 Apr 5 01:43 japanese-utf8.txt
表示の詳細
Apr: 01:44 などの更新日時 (ただし9時間時差があります),
中央付近の 2つのroot は colab でのユーザ名とグループ名 (ファイルシステムのルートではなく,管理権限を木構造であらわしたときにすべての権限をもつもの=管理者という意味です) と並んでいます.残りの説明は今は割愛します.ここまでをまとめると表のようになります.
| ファイルサイズ | euc | jis | sjis | utf8 |
|---|---|---|---|---|
| オリジナル | 783 | 855 | 783 | 1166 |
| zip後 |
日本語の文字1字あたり,utf8 では概ね 3バイト,他は2バイトで表現します.ファイルサイズと概ね一致していますね.
つづいて,4つのファイルを別々に zip で圧縮して,結果を比較しましょう
zip のコマンドは,zip 出力ファイル名 圧縮対象 です.
japanese-text/japanese-euc.jp を euc.zip に圧縮してみます.
adding: japanese-text/japanese-euc.txt (deflated 33%)
ファイルの大きさを調べるには,ls -l ファイルパス とします
-rw-r--r-- 1 root root 737 Apr 5 02:53 euc.zip
今回は,元のファイルサイズとあまり変わりませんでした.
他はどうでしょうか? 調べて表を埋めてみましょう.
| ファイルサイズ | euc | jis | sjis | utf8 |
|---|---|---|---|---|
| オリジナル | 783 | 855 | 783 | 1166 |
| zip後 | 737 |
実は1つのファイルだけはっきり減ります.どのように考えれば良いでしょうか.
演習 #
演習のデータをダウンロードします. japanese-text2.zip
zip ファイルの中には複数のテキストファイルがあり,どれも有名な小説の一節です. それぞれのファイルを呼んで,対応する小説のタイトルを当ててください.